Tutorial sobre el manejo de la plataforma VisigothicPal: intranet

En este post se explica cómo configurar la plataforma revisando las opciones disponibles en su intranet.
Después de los post anteriores espero haber podido resumir en qué consiste DigiPal, las plataformas “Pal”, y las ventajas que puede aportar el uso de éste o de programas similares al estudio de fuentes manuscritas, especialmente cuando agrupadas en corpora masivos. En este y los post que siguen me centraré en explicar cómo funciona exactamente mi “Pal”, VisigothicPal, como referencia para todos aquellos que os animéis a descargaros el programa y aplicarlo a vuestro corpus. [NB. Avisad antes a algún miembro del equipo “Pal” original. Se aceptan colaboraciones y nuevos proyectos, como mi “Pal”]. Empezaré comentando cómo es la intranet de VisigothicPal y cómo irla configurando paso a paso.
Primer vistazo
Una vez que habéis descargado e instalado el software en vuestro ordenador – también podéis subirlo online a vuestro server y acceder online, como en mi caso, pudiendo trabajar desde cualquier lugar y de forma colaborativa – , veréis todas la opciones disponibles para configurar vuestro “Pal” como si fuese una carcasa vacía. Es decir, todas las opciones están ahí pero no hay ningún tipo de contenido. Para visualizar la información el software creará un visor/web de uso local que, igualmente, aparecerá vacío. Para poder trabajar con el software, por tanto, lo primero será añadir la información, las imágenes de los documentos con los que queráis trabajar, etc. [NB. Si hacéis vuestra plataforma pública, recordar respetar las leyes de copyright de cada archivo aplicadas a cada imagen].
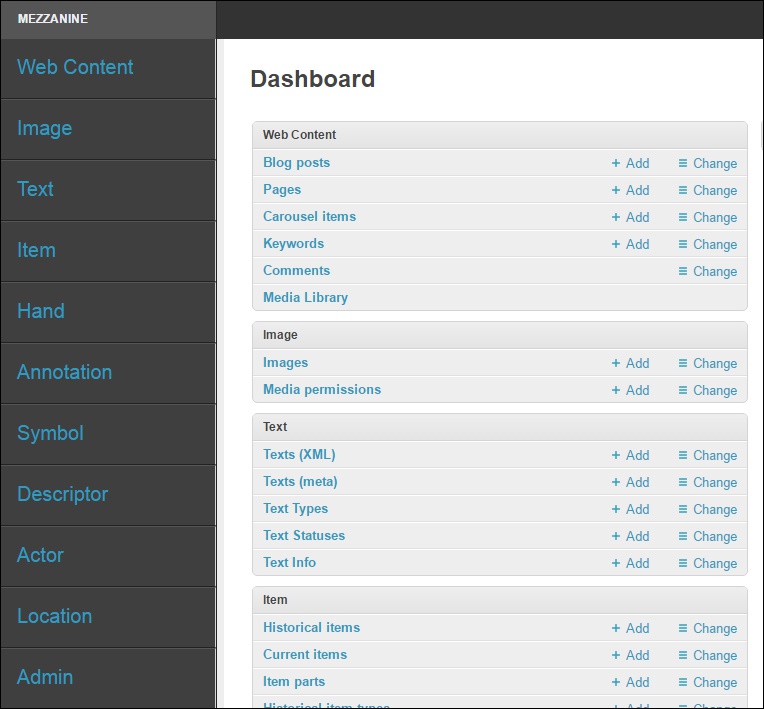
El sistema DigiPal o las plataformas “Pal” están todas construidas de la misma forma; mediante una base de datos relacional (podéis ver exactamente en qué consiste también en la web de DigiPal, en inglés). En pocas palabras, el programa almacena la información añadida relacionando un aspecto con otro por campos de tabla. En esa tabla cada elemento es único y tiene su propio espacio que enlaza una cosa con otra. Como veréis por la imagen arriba el aspecto externo es muy similar al de una plataforma WordPress por ejemplo (más concretamente Mezzanine), con las “categorías” a la izquierda y una página de inicio directo a las principales. Nosotros iremos “rellenando” la información que nos va a ir pidiendo cada apartado/categoría. El programa la almacena en esa tabla, establece las relaciones, y después presenta los resultados al visualizarlo en web, online u offline. Clasificar la información de esta forma hace que sea muy sencillo cambiar algo en el momento que queramos; por ejemplo, si queremos cambiar el nombre de X, solo tendremos que hacerlo una vez ya que el sistema lo cambiará también en todas las ocasiones en las que ese campo X sea requerido, o esté relacionado, con otro campo.
“Web content” o Contenido web
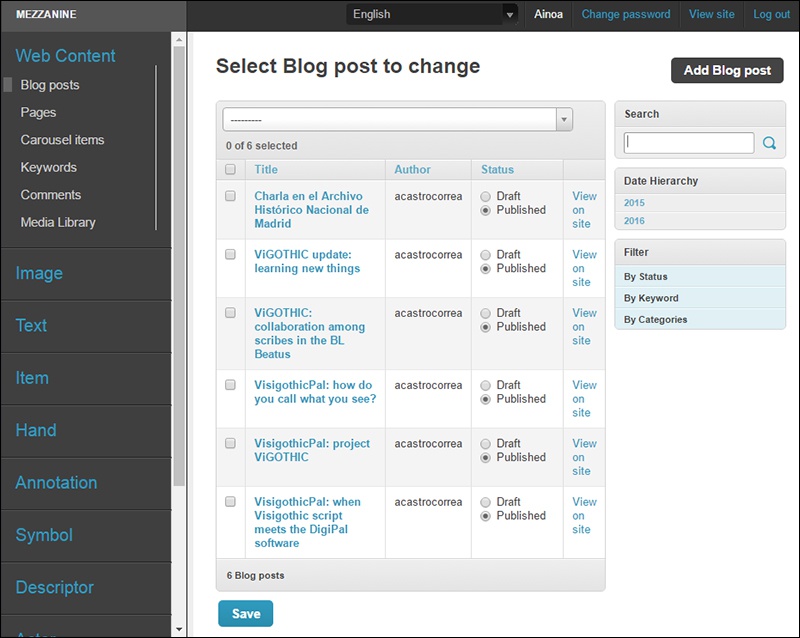
La primera categoría que tenemos disponible en el menú de la izquierda es la que nos da acceso al aspecto externo del visor de nuestro “Pal”, a su web, online u offline. A través de esa sección podremos añadir noticias o post al blog incorporado, gestionar las páginas de la cabecera, modificar el carrusel de imágenes, gestionar comentarios, o acceder a la librería de imágenes.
“Image” o Imagen
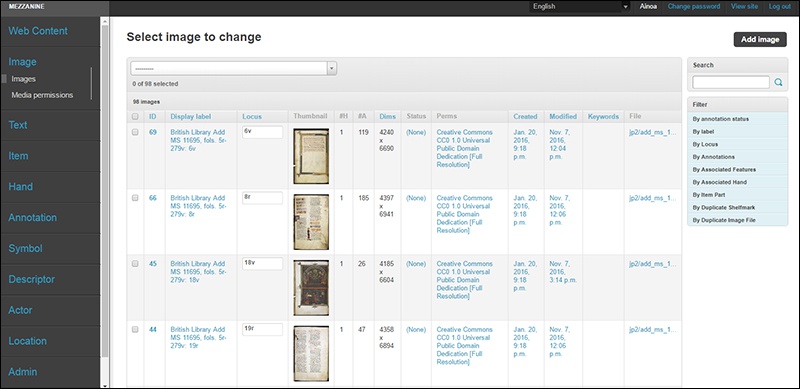
En la siguiente categoría, “Image” es donde iremos añadiendo a la plataforma las imágenes de nuestro corpus, ya sean diplomas, códices, inscripciones, monedas… Tened en cuenta que, por el nivel de detalle, la resolución debe ser alta, lo que requerirá considerable espacio en vuestro ordenador o servidor. Al seleccionar “add Image” nos aparecerán varios campos a rellenar (para más detalle ver ‘The Change List’). Al principio podéis completar los campos imprescindibles para el correcto funcionamiento de la base de datos (para ir el sistema clasificando la información). Siempre habrá tiempo para modificaciones una vez que uno se haya familiarizado con la plataforma.
“Text” o Texto
Esta categoría, que he comentado como introducida en el proyecto Models of Authority, no es operativa en mi proyecto actual por lo que no he experimentado con ella.
Item
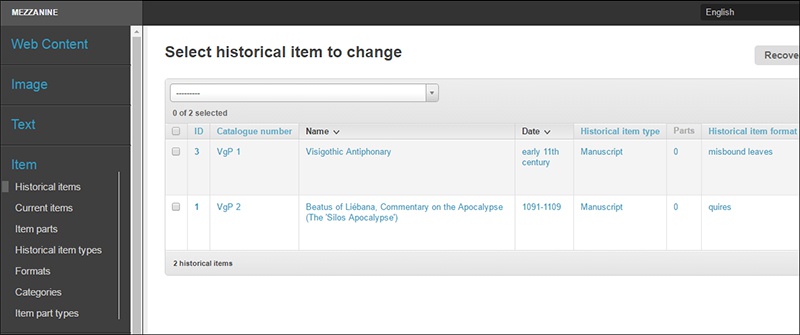
Esta sección es interesante. Cuando subimos las imágenes de nuestro corpus a la plataforma, puede darse el caso de que cada una de ellas corresponda con un ítem independiente o que forme parte de un conjunto. Del mismo modo, ese conjunto puede presentarse actualmente como formado por una serie de partes, pero quizás en origen estas no eran las partes constitutivas. Por ejemplo, VisigothicPal trabaja como corpus con el Beato de Silos, códice de finales del siglo XI en la British Library (Add. MS 11695). Este códice actualmente va precedido por una serie de folios que no forman parte del códice, aunque fueron añadidos a éste ya poco después de terminarse su copia. Por tanto, el “historical item” de este conjunto contendrá 2 ítems, los folios sueltos y el códice (dos ítems a añadir en “item parts”). El “current item” será el códice completo con sus dos partes (Add. MS 11695). “Historical item types” será manuscrito, “formats” hará referencia a 2 (los folios sueltos y los cuadernillos del códice), “category” a los contenidos, etc. Rellenando todos los campos dentro de esta categoría rellenaremos esa base de datos que relacionará un aspecto con otro. Y, como aspecto fundamental, sin establecer el conjunto al que pertenecen las imágenes añadidas a la plataforma, no podremos ordenarlas correctamente para continuar después el proceso de trabajo.
“Hand” o Mano
En la categoría “Hand” encontraremos 3 opciones: “hands”, “scribes” y “scripts”. La última es obvia; hemos de introducir el tipo de escritura a analizar en las imágenes. En relación a las otras dos, “scribes” hace referencia al número de escribas identificados en la fuente, mientras que “hand” a la mano de ese escriba X. Es decir, un mismo escriba puede tener varias manos, pero una misma mano no puede corresponder a dos escribas.
A medida que vayamos revisando el escriba responsable de cada manuscrito, hemos de crear su ficha correspondiente dentro de esta categoría para poder enlazar la información derivada de su mano en la plataforma.
“Annotation” o Anotación
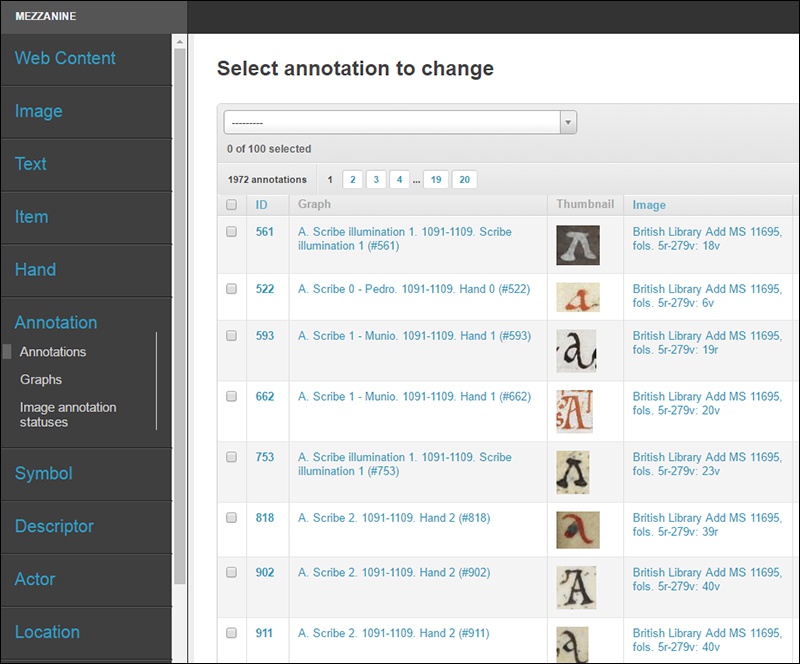
En esta categoría podemos revisar todos y cada uno de los recortes que vayamos haciendo durante el proceso de análisis de nuestra fuente o conjunto de fuentes, añadir notas internas, modificar existentes, o organizar la información por status (revisado/por revisar). No es, no obstante, la forma principal de acceso al proceso de anotación que comentaré en próximos post.
“Symbol” o Símbolo y “Descriptor”, campo descriptor
Son dos categorías principales mediante las cuales conseguimos comunicarnos con la plataforma transformando información “en imagen” a texto que el sistema puede procesar, clasificar y recuperar. Ambos casos, por tanto, implican la definición y uso de una serie de términos específicos a los que me referiré en próximos post.
“Actor” o Autor agente y “Location” o localización
En estas categorías crearemos las fichas correspondientes a aquellas personas, archivos o lugares por los que el manuscrito ha pasado para poder luego enlazarlas con las imágenes, ítems y demás.
La categoría final “Admin” engloba opciones de administración de la plataforma como enlaces a la url si por ejemplo trabajamos online, así como acceso a los registros de acceso (si trabajamos en grupo esta opción es muy útil para ver quién ha hecho qué).
En los próximos post volveré sobre el tema de cómo comunicarse con la plataforma (el lenguaje empleado en las “Pal”) y cómo funciona el proceso de anotación.
>>> seguir leyendo <<<
by A. Castro
[edited 13/07/2018]